Note
Click here to download the full example code
Artificial Vowels¶
This example implements the artificial vowels from Culling, J. F. and Summerfield, Q. (1995a). “Perceptual segregation of concurrent speech sounds: absence of across-frequency grouping by common interaural delay” J. Acoust. Soc. Am. 98, 785-797.
from brian2 import *
from brian2hears import *
duration = 409.6*ms
width = 150*Hz/2
samplerate = 10*kHz
set_default_samplerate(samplerate)
centres = [225*Hz, 625*Hz, 975*Hz, 1925*Hz]
vowels = {
'ee':[centres[0], centres[3]],
'ar':[centres[1], centres[2]],
'oo':[centres[0], centres[2]],
'er':[centres[1], centres[3]]
}
def generate_vowel(vowel):
vowel = vowels[vowel]
x = whitenoise(duration)
y = fft(asarray(x).flatten())
f = fftfreq(len(x), 1/samplerate)
I = zeros(len(f), dtype=bool)
for cf in vowel:
I = I|((abs(f)<cf+width)&(abs(f)>cf-width))
I = ~I
y[I] = 0
x = ifft(y)
return Sound(x.real)
v1 = generate_vowel('ee').ramp()
v2 = generate_vowel('ar').ramp()
v3 = generate_vowel('oo').ramp()
v4 = generate_vowel('er').ramp()
for s in [v1, v2, v3, v4]:
s.play(normalise=True, sleep=True)
s1 = Sound((v1, v2))
#s1.play(normalise=True, sleep=True)
s2 = Sound((v3, v4))
#s2.play(normalise=True, sleep=True)
v1.save('mono_sound.wav')
s1.save('stereo_sound.wav')
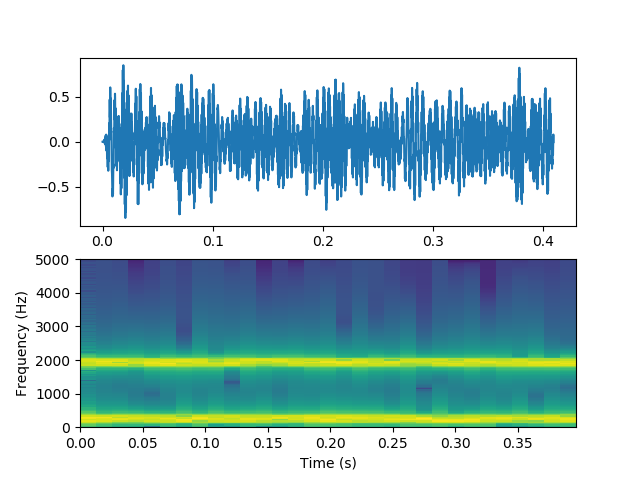
subplot(211)
plot(v1.times, v1)
subplot(212)
v1.spectrogram()
show()
Total running time of the script: ( 0 minutes 2.063 seconds)